Using On-Chain Data for Policy Research: Part 1
1. Introduction
Crypto policy work rarely involves real, granular data. It seems like there are (at least) three broad reasons for that:
- A lot of policy work in the emerging technology bucket is inherently theoretical/qualitative/analytical, so data is not always necessary or helpful in the early stages.
- Despite its openness/transparency, there’s a steep learning curve to accessing on-chain data (i.e., raw data pulled directly from the blockchain), even for relatively crypto-native practitioners.
- Blockchain “forensics” companies and data providers have a handful of data offerings, but nothing that’s flexible/customizable or that caters to the economics/finance research community.
This is a missed opportunity, given how many tools used by the modern economics and finance community should directly translate to crypto data analysis. Crypto offers granular data, available to anyone, by design. So why do a substantial number of policy papers still rely on pre-aggregated time-series data from external sources like CoinMarketCap instead of going directly to the source?
For example, with relatively little effort, it is possible to look at stablecoin issuance across the entire Ethereum ecosystem. This is roughly analogous to being able to query the balance sheets of every major bank in the U.S. and observe changes in consumer deposits on a second-by-second basis — but most policy papers that analyze stablecoins instead choose an analytical approach that talks about hypothesized events, like flights to safety, in the abstract.
In this blog post, I’ll demonstrate a few things that I hope will be helpful to policy researchers looking to work with on-chain data:
- Where to get on-chain data
- How on-chain data is structured
- A few basic tools for extracting and working with on-chain data
In subsequent posts, I’ll explore how to use the data collected here to draw inferences on crypto markets. I plan on eventually posting the data and code for free use, as well. By shedding light on how to “check the chain,” I hope to show how the crypto’s transparent nature enables a novel approach to data-informed policymaking.
If you work at a regulatory agency or research institution and are having difficulty accessing crypto data to work with, please don’t hesitate to reach out and share your thoughts about what Paradigm can do to help.
2. Where do you get on-chain data?
Short answer: it depends.
For the sake of bounding this particular project, I chose to focus my data gathering efforts on one blockchain (Ethereum) and a subset of specific projects: major USD-denominated, fiat-backed stablecoins. Specifically, USDC, Tether, Binance USD, Pax Dollar, and Gemini Dollar. The general approach I describe here should be broadly applicable to on-chain data, even if you’re looking to create a different set of data.
Block explorers like Etherscan are invaluable for viewing transaction snapshots and collecting information on specific smart contracts, but they aren’t particularly useful for generating large datasets in my experience. For collecting and working with raw data, you have essentially two options: (1) running a full node locally, or (2) querying a database that already has raw data that was written directly from the chain. Option (1) requires a considerable amount of technical skill and computational resources. You can get pretty far with Option (2) with very basic SQL and Python skills, so that’s the approach taken here.
Databases that already have on-chain data
Dune and Google Cloud Platform’s (GCP) BigQuery have up-to-date on-chain data structured in database tables that are queryable using SQL commands. Dune has a free option that is slower and somewhat limited, but it’s perfect for A/B testing queries and familiarizing yourself with the database schema, especially if you aren’t very experienced with using SQL to query relational databases. BigQuery is more flexible and faster, but Google charges for compute resources, so it can get expensive quickly. When I was first tinkering around the data, I would test queries in Dune before running in “production” in GCP to save money. For the most part, it worked well? (The one additional thing worth flagging is that Dune has at least 100x the number of crypto tables as GCP, including some pre-cleaned, user generated ones that are very valuable. By comparison, the data in GCP are mostly raw blocks/transactions. Dune also has some very handy built-in data viz tools that are probably worth the price of admission alone.)
3. How is on-chain data structured?
To answer this question, you first need to know what you’re trying to accomplish with the data you’re seeking. For this test case, I decided I wanted to build a large data set of time-series data for major fiat-backed stablecoins looking at a few specific actions: mints (i.e., issuing stablecoins), burns (i.e., taking stablecoins out of circulation), and transfers. I chose to scope the exercise this way because it seems like policymakers and academics are most interested in fiat-backed stablecoins at the moment, so that data could be quite useful in the short term.
The major USD-denominated stablecoins are implemented using the ERC-20 Token Standard. As the name suggests, ERC-20 is a standardized way for creating tokens on Ethereum using a smart contract. If you conceptualize a blockchain as a giant decentralized Excel spreadsheet, smart contracts are similar to the Excel functions that let you manipulate the data in the spreadsheet’s cells. Feed the function an input, known as an argument, and it will produce a specific output using its built-in logic (e.g., MAX(number 1, [number 2], …) finds the largest number among the numbers included in the function’s input arguments).
The relevant contracts can be located using their Ethereum addresses, which are a unique identifier in the blockchain’s data structure:
Smart contracts are programs that can be used repeatedly, similar to an API. Each time a smart contract is interacted with (e.g., asked to do something programmatically), a record of that interaction is produced and logged in the blockchain by the Ethereum protocol. These logs form a powerful source of information describing a smart contract’s activities. (For a longer explanation of Ethereum event logs, look here.)
When a smart contract performs a specific function, such as burning ERC-20 stablecoin tokens to remove them from circulation, that function — and the arguments it is fed — are recorded on the blockchain as a transaction log receipt.
Here is a transaction where Circle, the issuer of the USDC stablecoin, burned (i.e., removed from circulation) $1,056.92 worth of USDC.
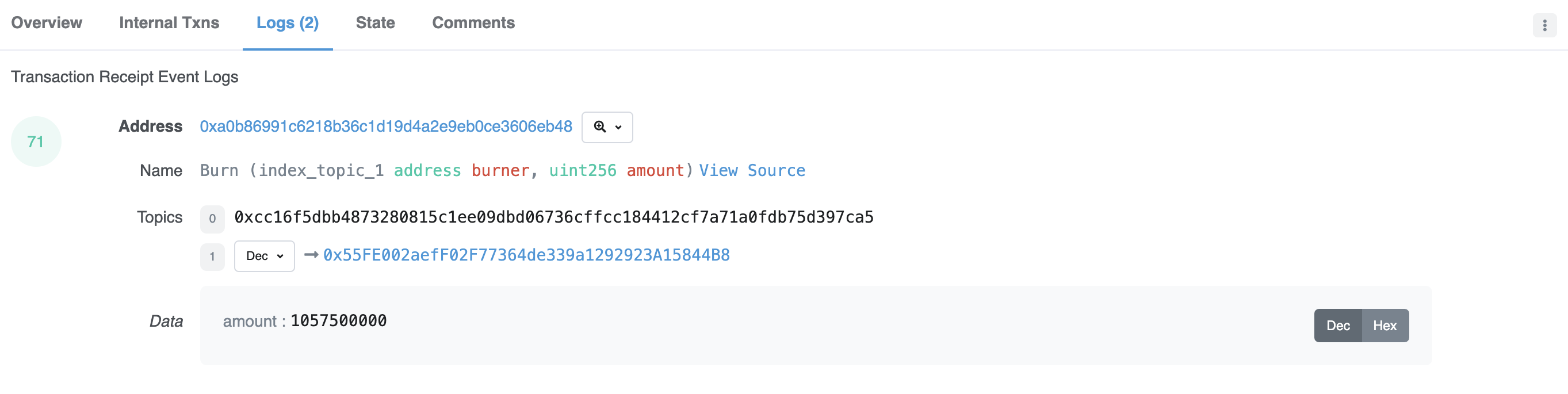
If you toggle over to the “Logs” tab, you can see the transaction event logs. The relevant fields are:
- Address: the contract address of the smart contract. The contract address for the USDC stablecoin is 0xa0b86991c6218b36c1d19d4a2e9eb0ce3606eb48.
- Name: the function executed by the smart contract, along with the parameters the function takes. In this case, the smart contract is calling the Burn function, which takes parameters that specify where the burned coins are sent (e.g. burner, which has to be an Ethereum address) and how many coins are being burned (e.g. amount, which has to be an unsigned integer smaller than 256 bits).
The Etherscan output also shows Topics and Data fields. These contain the bulk of the relevant information we need to parse to analyze transactions.1
- Topic0 is the hash of the signature of the function. Essentially, it takes the function and its arguments (i.e. the parameters) and puts them through a one-way algorithm that creates a unique hash — or fingerprint — of the function. Ethereum uses the Keccak-256 hash function. Putting the function signature (i.e. “Burn(index_topic_1 address burner, uint256 amount)”) through the Keccak-256 algorithm will always produce the same hash, so any time that hash appears in a log, you can be confident the same function was called.
- Topic1 is an indexed parameter of the Burn function. Here, Topic1 is the address where the burned coins are sent. (Note: If the Burn function took more parameters, those would appear as additional Topics.)
- The Data field here represents the amount of coins burned.

Now that we understand the basics of how on-chain data is structured for our use case, we can start pulling the data from Dune and/or GCP.
4. Basic tools for extracting and working with on-chain data
As noted previously, for this example I’ve chosen to pull on-chain data from existing databases as opposed to accessing an active node on the Ethereum network. To keep things simple, I’m extracting (mostly) raw tables from GCP using SQL, and then cleaning the data in Python using the pandas library.
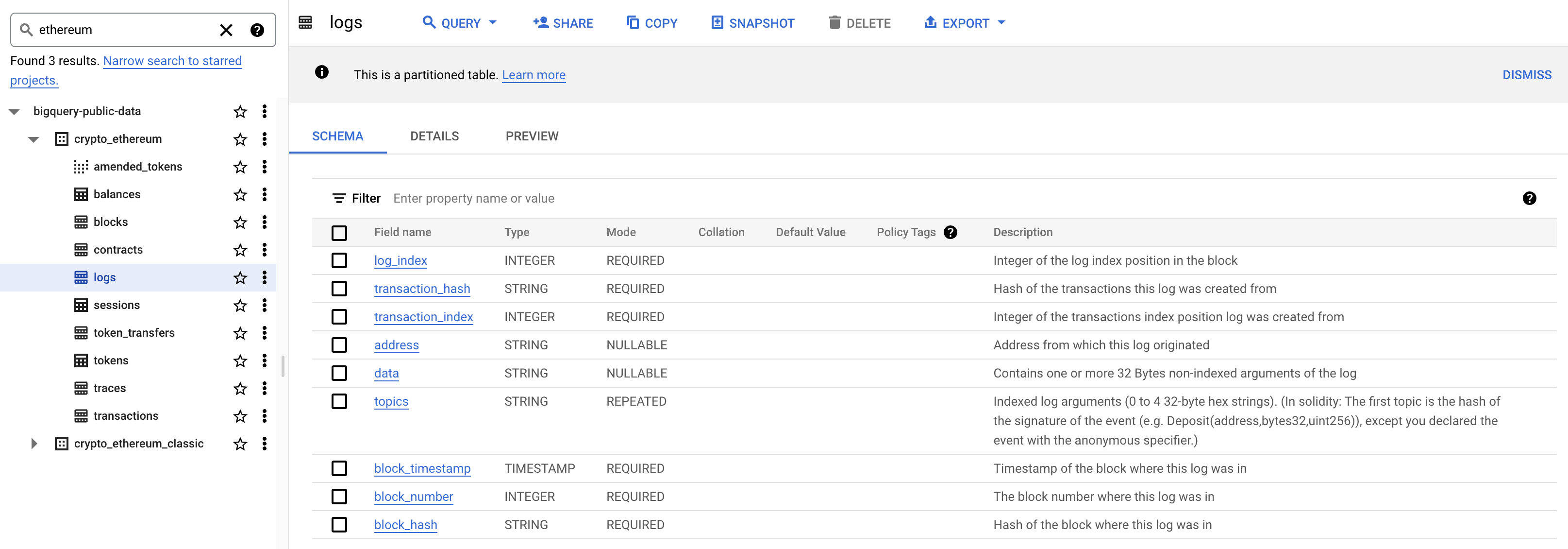
Extracting tables from GCP using BigQuery2
BigQuery has a lot of Ethereum tables, as seen in the left-hand pane of the image below. Clicking on a table brings up the database schema, which we can see here for the ethereum.logs table. Address, data, and topics map to the log data I described above from Etherscan.
The following query will extract all of the records in the logs table that involve an interaction with the USDC, Tether USD, Binance USD, Pax Dollar, or Gemini Dollar contracts. Some additional information is useful beyond what’s available in ethereum.logs, so I’ve also merged in data from the ethereum.blocks table to include things like gas (a measure of a network fee paid to Ethereum miners for validating transactions).3
SELECT
eth_logs.\*,
eth_blocks.number, eth_blocks.miner, eth_blocks.size, eth_blocks.gas_limit, eth_blocks.gas_used, eth_blocks.base_fee_per_gas
FROM
`bigquery-public-data.crypto_`ethereum.logs`` AS eth_logs
LEFT JOIN
`bigquery-public-data.crypto_ethereum.blocks` AS eth_blocks
ON
eth_logs.block_number = eth_blocks.number
WHERE(
eth_logs.address='0xa0b86991c6218b36c1d19d4a2e9eb0ce3606eb48'-- USDC
OR eth_logs.address ='0xdac17f958d2ee523a2206206994597c13d831ec7' -- USDT
OR eth_logs.address ='0x4fabb145d64652a948d72533023f6e7a623c7c53' -- Binance USD
OR eth_logs.address = '0x8e870d67f660d95d5be530380d0ec0bd388289e1' -- Pax Dollar
OR eth_logs.address = '0x056fd409e1d7a124bd7017459dfea2f387b6d5cd' -- Gemini Dollar
)The resulting table can be read directly into Python as a pandas dataframe with the following fields:
- log_index
- transaction_hash
- transaction_index
- address
- data
- topics
- block_timestamp
- block_number
- block_hash
- number
- miner
- size
- gas_limit
- gas_used
- base_fee_per_gas
Most of these fields are ready-to-use in raw form. However, the topics field discussed in Section III requires some additional cleaning with Python to separate the field into multiple columns.4
5. Conclusion
This post leveraged Ethereum logs data, but the same approaches can be used to access a variety of data available on the chain. Python and SQL, tools that most economists and policymakers are familiar with, can go a long way. Crypto’s transparency, relative to traditional finance, offers a unique opportunity for researchers to use real-time data to shed light on how the financial system functions, including where risks may arise unchecked.
In the next post I’ll prep the data set for a targeted analysis looking at minting and burning of fiat-backed stablecoins. In post number three, I’ll display a few charts and tables as an example of the kind of research questions that people can examine using granular on-chain data.
6. Caveats
A few additional notes/disclaimers:
- Transactions are not unique in this data set. In Ethereum, a transaction is a change in state of the Ethereum Virtual Machine (EVM). Each transaction can have multiple, distinct logs that interact with the same contract address. These are indexed by the “log_index” variable, such that each observation is uniquely identified by a “log_index” and “transaction_hash” combination.
- The Transfer function can describe a number of different scenarios, depending on the accounts that are being invoked in the function’s arguments. In some cases, it will be referring to the transfer of tokens from one externally-controlled account to another. In other cases, it could describe the transfer of tokens from one externally-controlled account to an account controlled by another smart contract, like a DeFi protocol. For now, I’ve kept the transfers in raw form and have not mapped out every account address, so keep this in mind if you are trying to draw inferences from the transfer data. The Mint and Burn functions have a more straightforward interpretation. For the other functions in the dataset… you’ll have to get more familiar with Solidity.
- Being that this is on-chain data, it only shows things that happened on-chain. So, transfers of USDC between Circle customers that happen on the books of Circle (e.g., off-chain) would not be reflected in the data.
Acknowledgements
Huge thanks to Dan Lee for help on the tech side, and for Anthony Lee Zhang for the idea to focus on fiat-backed stables as a first pass!
Footnotes
-
Note: the Topics and Data fields have different interpretations depending on the type of function that is being called. ↩
-
This post does not walk through how to set up an account for accessing BigQuery, but you can find out how to do that here. ↩
-
GCP has some restrictions on query size that make it difficult to run this query directly. If you look at the actual code when it is posted, you’ll see I had to deal with this issue by breaking the query into smaller pieces and looping/aggregating the results using Python and the GCP BigQuery API. More info here. There are probably less clunky ways to do this, but where’s the fun in that. ↩
-
The
ethereum.logstable in GCP records all of the topics for a transaction log as a single string, delimited by commas. In order for this to be useful for research, I separated the topics into individual fields: topic0, topic1, and topic2. ↩